Once in a while, when work and family permits, I take a day off to dive deep into something technical. In the past this has been hacking on OpenBSD, writing a BASIC compiler on paper, or tweaking Ham Radio electronics, building short-wave antenna & tracking propagation.
Today I am in monk mode and diving deep into GPTs.
This is a collection of links to materials, which I am studying:
- pdf: Attention Is All You Need (from arxiv.org)
- video: Let’s build GPT: from scratch, in code, spelled out by Andrej Karpathy
- The spelled-out intro to neural networks and backpropagation: building micrograd by Andrej Karpathy Aug 16, 2022
notes on: Attention Is All You Need
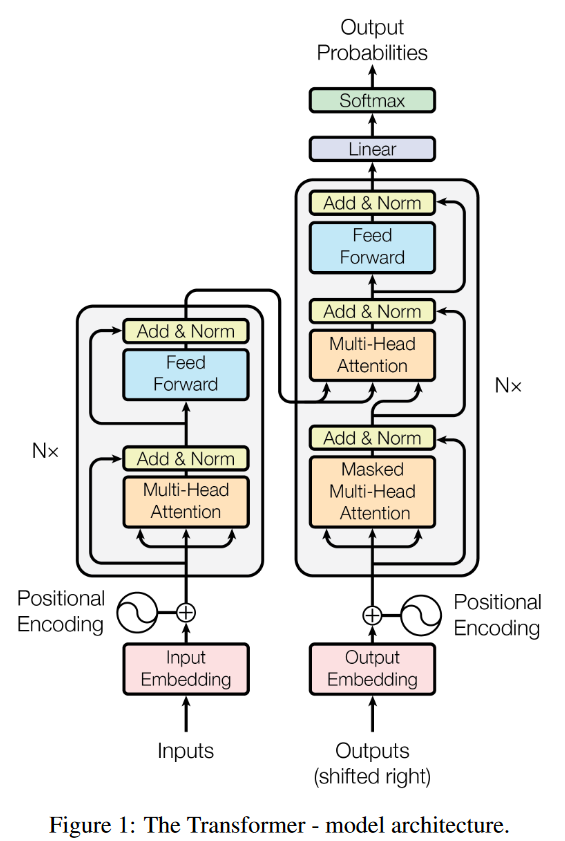
Tokenizers
- GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation. · GitHub
- GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI's models. · GitHub
News Articles (that may be) Worth Reading
- 8 Google Employees Invented Modern AI by Steven Levy for Wired, Mar 20, 2024 (archive, pocket)
- Meet the $4 Billion AI Superstars That Google Lost by Parmy Olson, for Bloomberg July 13, 2023 (archive, pocket)
- Transformers: the Google scientists who pioneered an AI revolution by Madhumita Murgia for The Financial Times July 23 2023 (archive, pocket)
- https://medium.com/nearprotocol/will-near-blockchain-lead-the-breakthrough-of-ai-87d158991fdb
- Google Blog: Transformer: A Novel Neural Network Architecture for Language Understanding by Jakob Uszkoreit (Google SWE) on August 31, 2017
- Microsoft Hires DeepMind Co-Founder to Lead Consumer AI Unit by Tom Dotan at WSJ (archive, pocket)
Social Media Posts
Notable People in AI
- Mustafa Suleyman → DeepMind → co-founder Inflection AI
Authors of All You Need Is Attention paper:
| name | formerly of | now title | company |
|---|---|---|---|
| Ashish Vaswani | Google Brain | Co-Founder and CEO | Essential AI |
| Noam Shazeer | Google Brain | Chief Executive Officer and Co-Founder | Character.AI |
| Niki Parmar | Google Research | Co-Founder | Essential AI |
| Jakob Uszkoreit | Google Research | Co-Founder and Chief Executive Officer | Inceptive |
| Llion Jones | Google Research | Co-Founder and Chief Technology Officer | Sakana AI |
| Aidan Gomez | University of Toronto | Co-Founder and Chief Executive Officer | Cohere |
| Lukasz Kaiser | Google Brain | Member of Technical Staff | OpenAI |
| Illia Polosukhin | Google Research | Co-Founder | NEAR Protocol |
Transforming AI [S63046] session at NVIDIA GTC
Wednesday, Mar 2011:00 AM - 11:50 AM PDT (2:00 PM - 2:50 PM EDT)
video recording: https://www.youtube.com/watch?v=xGMKtCyhqVs
Panelist
- Jensen Huang, Founder and Chief Executive Officer, NVIDIA
- Ashish Vaswani, Co-Founder and CEO, Essential AI
- Noam Shazeer, Chief Executive Officer and Co-Founder, Character.AI
- Jakob Uszkoreit, Co-Founder and Chief Executive Officer, Inceptive
- Llion Jones, Co-Founder and Chief Technology Officer, Sakana AI
- Aidan Gomez, Co-Founder and Chief Executive Officer, Cohere
- Lukasz Kaiser, Member of Technical Staff, OpenAI
- Illia Polosukhin, Co-Founder, NEAR Protocol
Interesting Links, Project and Repositories
- https://tinygrad.org/, X, bounties
 → Summary of all AI news, conversations, social media posts: AI News (MOVED TO news.smol.ai!) • Buttondown
→ Summary of all AI news, conversations, social media posts: AI News (MOVED TO news.smol.ai!) • Buttondown 
- https://karpathy.ai/
- Andrej Karpathy’s nanoGPT
- Andrej Karpathy’s ng-video-lecture
Glossary
ReLU→ Rectified Linear Unit is a an activation function used in neural networks, and especially in deep learning models →ReLU(x)=max(0,x)autograd→ a key component within many machine learning and deep learning libraries, such as PyTorch, TensorFlow (through its eager execution mode), and others, including the smaller frameworks like micrograd or tinygrad we discussed. It stands for automatic differentiation, a technique for automatically computing the gradients of tensors with respect to other tensors in a computation graph.micrograd→ “tiny scalar-valued autograd engine and a neural net library” from Andrey Karpathy. It has a PyTorch-like API. Micrograd implements backpropagation (reverse-mode automatic differentiation) over a dynamically built directed acyclic graph (DAG) and comes with a small neural networks library on top of it. Micrograd operates over scalar values, decomposing each neuron’s operations into individual adds and multiplies, yet it’s capable of building entire deep neural networks for binary classification. This project is particularly useful for understanding the fundamentals of neural networks and the autograd mechanismtinygrad→ simple & powerful neural network framework. It is a a bridge between PyTorch and Micrograd. It emphasizes extreme simplicity and efficiency, breaking down complex networks into four operation types: UnaryOps, BinaryOps, ReduceOps, and MovementOps, facilitating operations like ReLU, logarithm, addition, multiplication, summation, and reshaping among others. Tinygrad supports features like running LLaMA and Stable Diffusion models and provides laziness in computations, fusing operations into a single kernel for efficiency. The project is maintained by Tiny Corp and targets both educational purposes and practical applications in machine learning, with aspirations to accelerate development and commoditize petaflop-scale computing for broader AI accessibilityRAG→ Retrieval-Augmented Generation, is a method used in the context of Language Models (LMs), Artificial Intelligence (AI), and Machine Learning (ML) that combines the capabilities of a traditional language model with a retrieval system. The goal of RAG is to enhance the performance of language models by enabling them to pull in information from a large database or corpus of texts in real-time as they generate text. This approach helps in improving the accuracy, relevance, and quality of the generated content, particularly for tasks that require detailed knowledge or factual information.
Here’s how RAG works in a simplified form:
- Retrieval: When given a prompt or question, the system first searches a large dataset or document collection to find relevant information. This dataset could be anything from a curated corpus of texts, Wikipedia, or any large-scale database of knowledge.
- Augmentation: The relevant information retrieved in the first step is then provided to the language model as additional context or augmentation. This helps the language model understand the context better or access detailed information that might not be contained within its pre-trained knowledge.
- Generation: With the augmented information, the language model then generates a response or continues the text. The additional context allows the model to produce more accurate, detailed, and relevant outputs than it could by relying solely on its internal knowledge.
- What is RAG? - Retrieval-Augmented Generation AI Explained - AWS
- https://www.youtube.com/watch?v=T-D1OfcDW1M&t=214s
- tensor
- array
- loss function
- Tensor feeds into the Transformer
- bi-gram language model - simplest language model
- logits - scores for the next character in the sequence
Lessons Learned
Autograd
Autograd is a key component within many machine learning and deep learning libraries, such as PyTorch, TensorFlow (through its eager execution mode), and others, including the smaller frameworks like micrograd or tinygrad we discussed. It stands for automatic differentiation, a technique for automatically computing the gradients of tensors with respect to other tensors in a computation graph.
How Autograd Works
In essence, autograd automates the process of taking derivatives, which is crucial for the optimization steps in training models, such as neural networks. When you perform operations on tensors in a framework that supports autograd, the framework keeps track of these operations and builds a graph, where the nodes represent the tensors, and the edges represent the functions that produce output tensors from input tensors.
The Computation Graph
This graph is a directed acyclic graph (DAG), where the directionality represents the flow of data and the computations that transform that data. Each node in the graph has a forward pass, where the actual computation takes place, and a backward pass, where gradients are computed using the chain rule.
The Chain Rule and Backpropagation
The backward pass is essentially the application of the chain rule of calculus to compute the gradient of a desired output tensor with respect to any tensor in the graph. In the context of neural networks, this gradient calculation is essential for the backpropagation algorithm, which adjusts the weights of the network to minimize the loss function.
Why Autograd is Important
Autograd significantly simplifies the implementation of machine learning algorithms, as it abstracts away the complex calculus and bookkeeping involved in computing gradients. It allows researchers and developers to focus more on the architecture and design of their models rather than the details of gradient computation.
Advantages of Using Autograd
- Simplicity: Autograd abstracts the complexity of derivative computation, making model implementation more straightforward.
- Flexibility: It allows for dynamic computation graphs. For example, in PyTorch, the graph is rebuilt from scratch at each iteration, allowing for models with conditional control flows and variable-length inputs.
- Efficiency: By automating gradient computation, autograd systems can optimize the process and improve computational efficiency, making it feasible to train large and complex models.
In summary, autograd is a fundamental feature in modern deep learning libraries, enabling the automatic and efficient calculation of gradients, which is crucial for training neural networks. Its development and integration into these libraries have significantly advanced the field of machine learning by simplifying the process of model building and experimentation.
Backpropagation
Backpropagation, short for “backward propagation of errors,” is a fundamental algorithm in the field of neural networks and deep learning, essential for training artificial neural networks. It refers to the method of calculating the gradient (or direction and rate of change) of the loss function with respect to each weight in the network by propagating the loss backward through the network’s layers. This process allows for efficient optimization of the weights, thereby minimizing the loss and improving the model’s performance on given tasks.
How Backpropagation Works
- Forward Pass: The input data is passed through the network layer by layer until the output layer is reached. This process generates predictions, which are then used to calculate the loss (or error) by comparing the predictions against the true values.
- Backward Pass: The backpropagation algorithm computes the gradient of the loss function with respect to each weight in the network by traversing the network in reverse order. It starts from the output layer and moves towards the input layer. This backward pass involves the application of the chain rule from calculus to compute the gradients efficiently.
- Update Weights: Once the gradients are calculated, the weights are updated using an optimization algorithm, typically gradient descent or one of its variants. The size of the step taken in the direction of the negative gradient is determined by the learning rate, a hyperparameter that controls how much the weights are adjusted during each iteration.
Importance of Backpropagation
- Learning: Backpropagation is the mechanism by which neural networks learn from the training data. By adjusting the weights that minimize the loss, the network learns to make more accurate predictions.
- Efficiency: Before the advent of backpropagation, adjusting the weights of networks with many layers was computationally infeasible. Backpropagation, combined with chain rule, allows for the efficient computation of gradients across layers, making the training of deep networks possible.
- Versatility: Backpropagation is not tied to a specific type of neural network architecture (e.g., convolutional, recurrent) or a specific task (e.g., classification, regression). This universality makes it a powerful tool in the deep learning toolkit.
Limitations and Challenges
- Vanishing/Exploding Gradients: In very deep networks, gradients can become very small (vanish) or very large (explode) as they are propagated back through the network, making learning either very slow or unstable. Various techniques, such as normalization layers, modified activation functions, and careful initialization, have been developed to mitigate these issues.
- Requirement for Differentiable Activation Functions: For backpropagation to work, the activation functions used in the network must be differentiable. This requirement excludes certain types of non-continuous functions but still allows for a wide range of functions to be used.
Backpropagation has been instrumental in the successes of deep learning, enabling the training of complex models that power many of today’s AI applications, from image and speech recognition to natural language processing. Despite its limitations, ongoing research continues to refine and complement backpropagation, ensuring its place in the future of machine learning.
Tensors, PyTorch, Google TPUs
In PyTorch, tensors are specialized data structures similar to arrays and matrices. They are used to encode the inputs, outputs, and parameters of a model. Tensors can run on GPUs or other hardware accelerators, which distinguishes them from NumPy’s ndarrays, though they can often share the same underlying memory. Tensors are also optimized for automatic differentiation, which is crucial for training models
A Tensor Processing Unit (TPU) is a custom-developed accelerator specifically designed for deep learning tasks, used in Google data centers. It significantly speeds up machine learning workloads by providing highly efficient matrix computations, which are a cornerstone of deep learning algorithms.
GPT vs LLM
GPT (Generative Pre-trained Transformer) refers to a specific series of AI models developed by OpenAI, focusing on generating human-like text based on the input it receives. It’s pre-trained on a diverse range of internet text and then fine-tuned for specific tasks. LLM, or Large Language Model, is a broader term that encompasses any large-scale model capable of understanding and generating human language, including GPT and others like BERT or T5. Essentially, GPT is an instance of an LLM, designed with a specific architecture and training methodology.